
Adaptive radix tree:高效自适应树状索引结构
文献阅读:The adaptive radix tree: ARTful indexing for main-memory databases
高效内存索引:Adaptive Radix Tree - 知乎 (zhihu.com)
数据库索引数据结构总结——ART树就是前缀树_11898275的技术博客_51CTO博客
高级数据结构与算法 | 自适应基数树(Adaptive Radix Tree)-CSDN博客
论文阅读: The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases - 知乎 (zhihu.com)
Trie
我们以每个节点存 2-bits 为例,假设 Trie 中存储了 7, 10, 12,从下图可以看到这三个数的二进制表示。每个节点的值由 0 和 1 组成,同时每个节点包含指向所有子节点的指针,指针为 * 代表该子节点存在,指针为 Ø 代表改子节点不存在。最终由叶子节点指向实际的数据。
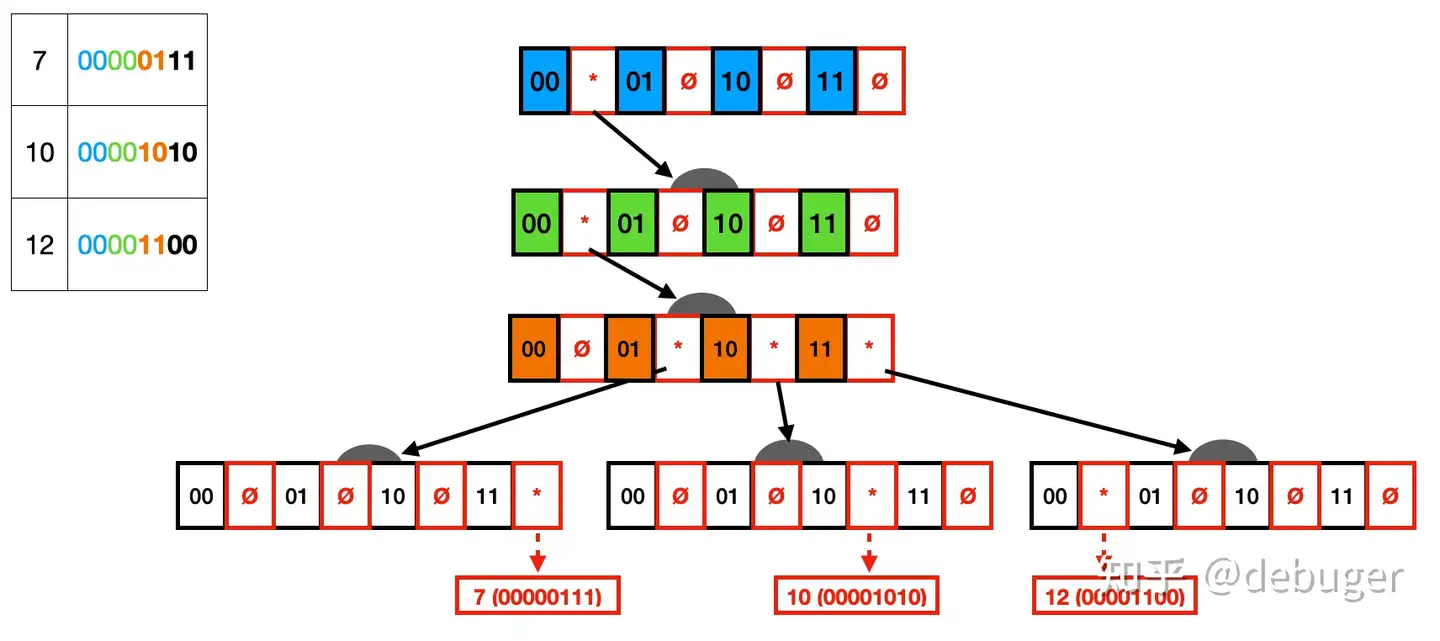 img
img
Radix Trie
压缩后的节点需要将路径的前缀存储下来,如下:
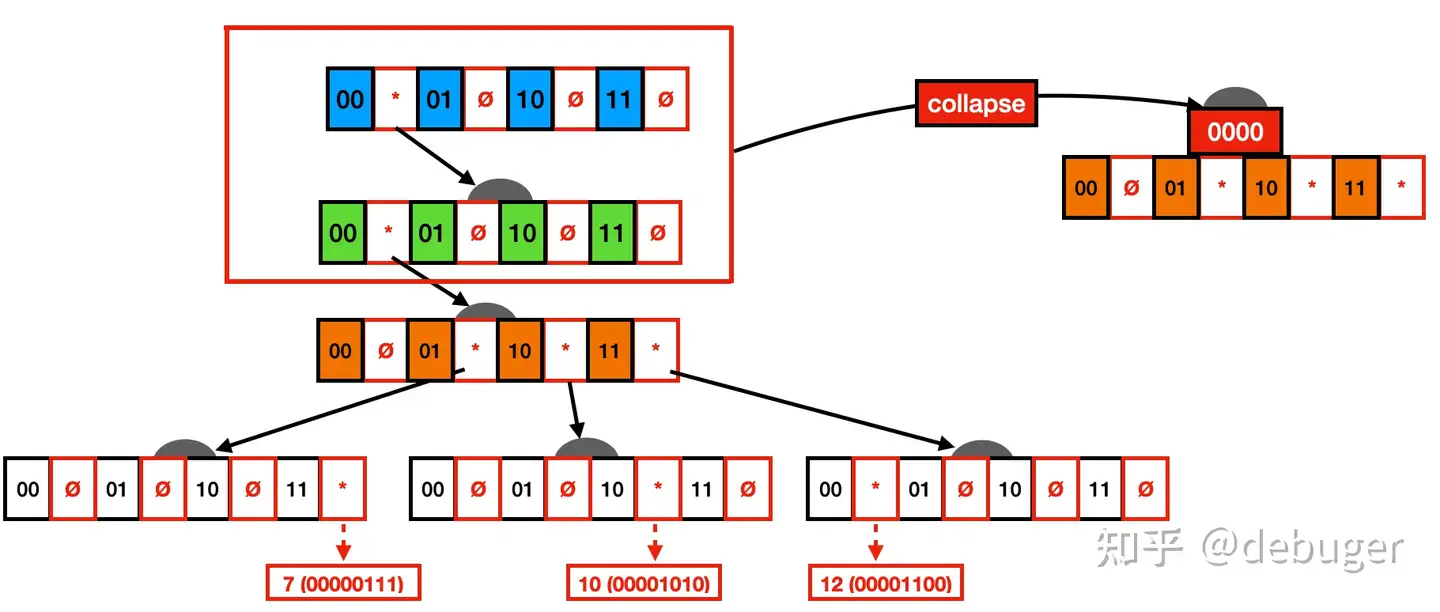 img
img
前两层的节点都只有一个子节点,将它们折叠到第三层的节点,保存折叠路径的前缀 0000,形成一个新节点,如下所示:
 img
img
查找时,遇到折叠过的节点,要比较前缀是否匹配。经过垂直压缩,减少了节点树和层级树,节约了大量空间,但是依然没有解决空指针浪费的问题。
AdaptiveRadixTree
基本介绍
论文链接:
The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases
The ART of Practical Synchronization
Adaptive Radix Tree(ART)是由 Phil Bagwell 在 2000 年提出的一种基于 Trie Tree 实现的数据结构,旨在解决 Trie Tree 在空间效率和查找性能方面存在的问题。与其他基于 Trie 的数据结构(如 Radix Tree、Digital Search Tree)相比,其引入了自适应节点,高度压缩等特性,具有更好的空间效率和更快的查找速度。
相对于传统的基于比较的搜索树(如红黑树、AVL 树、B+ 树),ART 具有以下特点:
- ART 的高度取决于 Key 的长度,而非树中元素的数量。
- ART 不需要平衡操作,且所有插入顺序产生的树都是相同的。
- Key 按照字典序进行存储。
- 从根节点到叶子节点的路径代表着其对应的 Key,因此 Key 是隐式存储的,可以通过路径重新构造。
假设字符串比较操作开销为 O(1),字符串长度为 k,基于比较的搜索树的查询复杂度为 O(klogn),而 ART 为 O(k)。
ART 适用于许多高效查找的应用场景,例如数据库内存索引,路由表等。
自适应节点
ART 中包含了两种类型的节点:
- 内部节点:内部节点,将 key 映射到其他节点,用于表示路径。
- 叶子节点:存储实际的 value 数据。
内部节点
根据容量不同,ART 内部节点使用了四种不一样的内部结构。
Node4
Node4 是最小的节点类型,其由 4 个 key 以及对应 4 个子指针组成。key 和子指针存储在相同的位置,并以 key 为基准进行排序。
 img
imgNode4,由一个长度为 4 的 byte 数组和长度为 4 的指针数组构成,最多存储 4 个不同的 key 及其对应的子节点指针。一共占用 40(41 + 48)bytes。有效指针个数小于等于 4 时,使用这种类型的节点存储如下:
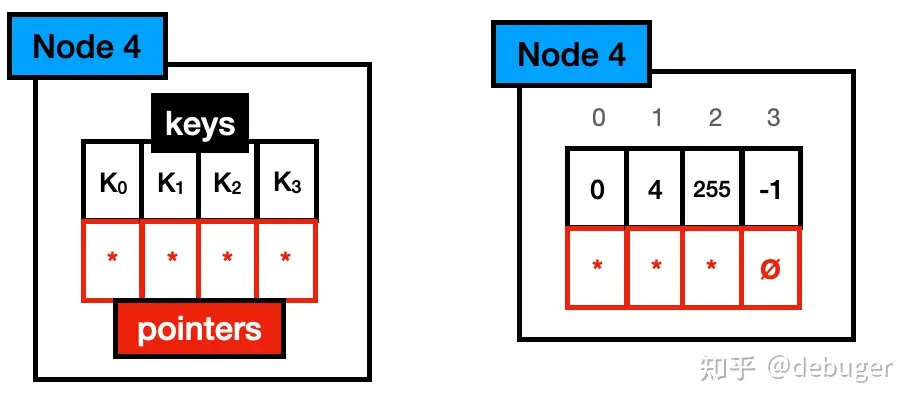 img
img查找时,需要遍历 byte 数组,判断当前要查找的 key 是否在数组中。由于数据长度小,遍历的开销也就很低。
Node16
- Node16 是 Node4 的扩容版本,其存储着 16 个 key 和子指针。
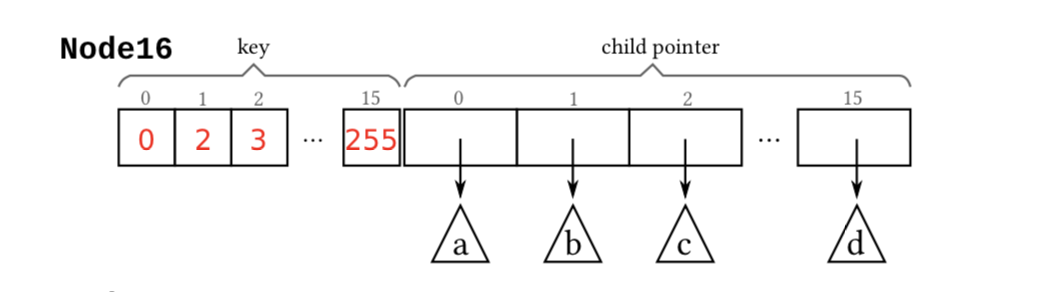 img
img
- Node16 是 Node4 的扩容版本,其存储着 16 个 key 和子指针。
Node48
由于节点中存储的内容增加,遍历 key 数组的开销也随之增加,因此 Node48 采用了另一种存储方式,不再显式存储 key,而是由一个长度为 256 的索引和 48 个指针组成。索引的每个位置正好对应了
unsigned char类型的 0~255。每个索引的对应位置存储了对应子指针的下标(不存在的始终标记为 0)。这里为了节省空间,带来了间接查询的开销。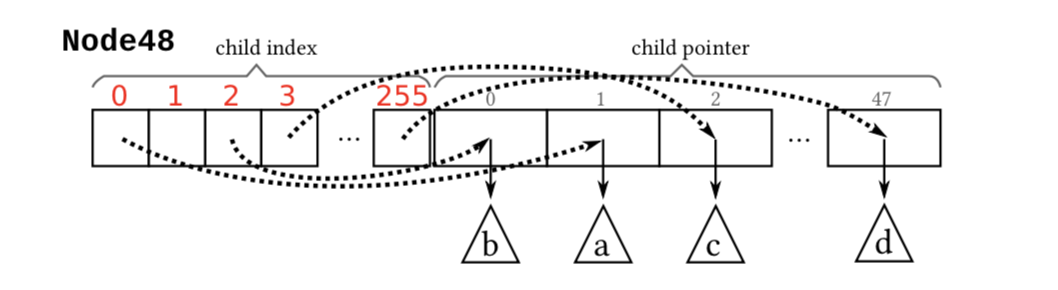 img
img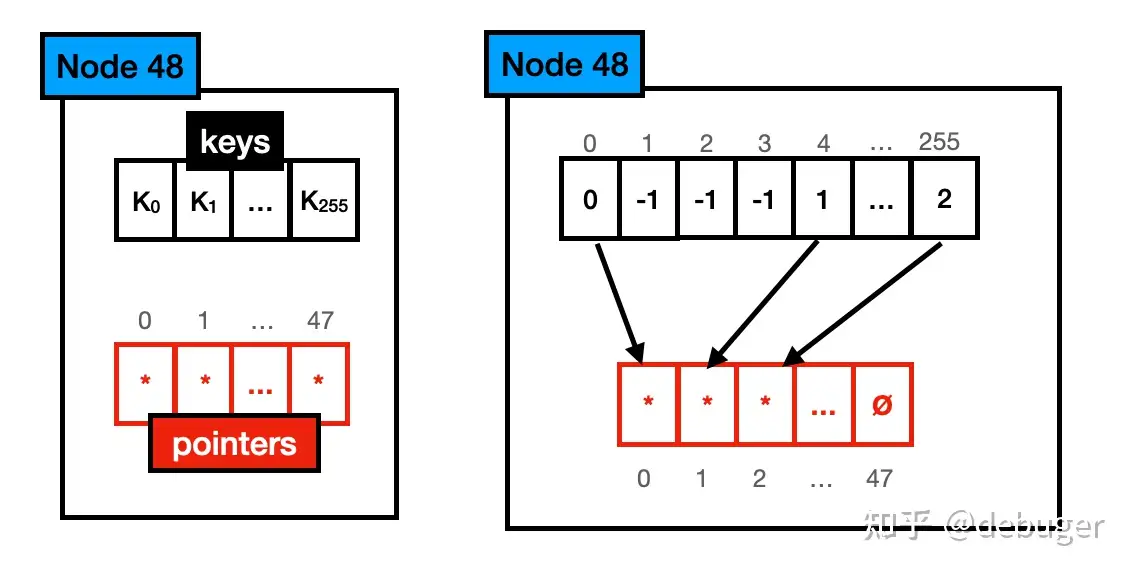 img
img由于 byte 数组和指针数组长度不对齐,需要通过一定的方式将它们映射起来:byte 数组的下标表示 key,值表示 key 对应的子节点指针在指针数组的位置。
查找 Node48 时,我们可以跟据查找的 key 快速定位到其在节点中的位置(key的值便是下标值),获取其对应的子节点指针。时间复杂多为 O(1) ,这是典型的空间换时间做法,但需要多一次内存访问时间。
Node256
Node256 是一个包含了 256 个指针的数组,相比较与 Node48,其一次查询即可得到结果。由于只存储指针,即使大部分位置为空,也不会过于浪费空间。
 img
imgNode256,由长度为 256 的指针数组构成,一共占用 2048(256 * 8)bytes。有效指针个数在 49~256 时,使用这种类型的节点存储,如下:
 img
img指针数组的下标代表 key,值代表其对应的子节点指针。查找是,可以快速得到子节点指针,时间复杂度为 O(1) 。
每个内部节点中还包含了一个 header,用于存储节点类型、子节点数量和压缩的路径以及 span(标识压缩路径的深度)。
叶子节点
除了内部节点存储的路径之外,ART 还需要将 value 存储在叶子节点上。假设只存储唯一 key,叶节点可以使用以下三种不同的结构:
- 单值叶节点:使用额外的叶节点类型存储一个值。
- 多值叶节点:使用四种不同的叶节点类型之一来存储值,这些叶节点类型可以复用内部节点的结构,但存储值而不是指针
- 组合指针/值 slot:如果值适合指针,则不需要单独的节点类型。相反,内部节点中的每个指针存储位置可以存储指针或值。每个指针可以使用一个额外的附加位或在指针中做标记来区分。
单值叶节点是最通用的方法,其允许在一个树中使用不同长度的 key 和 value。但是,由于树高度的增加,每次查找的时候都会有一次额外的指针遍历。
多值叶节点避免了这种开销,但要求树中的所有 key 具有相同的长度。
组合指针/值 slot 是最高效的,允许存储不同长度的 key。通常情况下都会考虑使用这个,它特别适用于存储元组标识符或与指针相同大小的数据库二级索引。
与其他数据结构比较
数据库常用的索引结构有 Hash 索引、B+ Tree 等,那么 ART 对比这些索引有什么优势呢?
ART 通过路径压缩、自适应节点分配极大的减少了空间浪费。相比 B+ Tree,其内部节点更小,占用空间更少,更适合 cpu cache,在纯内存场景,ART 优势明显。同时 ART 也拥有极佳的点查性能(最坏情况为 O(k) ),也更适合前缀匹配查询。
B+ Tree 的优势在于树高度小且平衡,更适合作为传统数据库的磁盘索引。B+ Tree 能提供稳定高效的查询性能,且范围查询性能也很突出。因此作为磁盘索引,B+ Tree 更有优势。
 数据库索引数据结构总结——ART树就是前缀树_数据库
数据库索引数据结构总结——ART树就是前缀树_数据库
Hash 索引常常能提供高效的点查性能,但是范围查询、前缀查询性能极差(全扫)。因此,Hash 索引常常用于加速点查,使用比较局限。
高度压缩
如下图,为了节省空间,ART 中采用了 Path Compression(路径压缩) 和 Lazy Expansion(惰性拓展) 两种技术来尽可能的减少节点数量,压缩树的高度。
 img
img
Path Compression && Lazy Expansion
Path Compression
Path Compression 用于移除只有单个子节点的节点,例如图左侧中,B 节点仅有单个子节点 A,此时会将它们合并为 BA。由于合并后出现了前缀,此时需要在存储结构中将其表述出来,通常有以下两种方式:
- 悲观:每个节点额外使用一个变长 vector 存储前缀,在查找过程中要额外对其进行比较,因此称为悲观。
- 乐观:用一个计数器记录前缀的长度,向下遍历时跳过这个长度,到了叶子节点后在回头进行前缀的比较。
悲观策略使用更多的空间,同时变长 vector 可能会导致内存碎片。而乐观策略则增加了额外的字符串比较开销。由于两者各有优缺点,在 ART 中会根据使用场景的不同来决定具体的策略。默认使用悲观策略,每个节点最多存储 8 字节的前缀,如果超过这个大小,则切换到乐观策略。
Lazy Expansion
Lazy Expansion 指的是只有在需要使用内部节点来区分两个叶子节点时,才会创建内部节点。如上图右侧,在 F 路径中只存在 FOO 单个节点,不需要区分,因此两个 O 节点会被删除掉,只有再插入另外一个共享前缀 F 的节点时才会拓展。
算法
Search
 img
img
查找算法
上图为查找逻辑的伪代码,执行的流程如下:
- 判断节点是否为空,如果空则返回,否则继续。
- 判断节点是否为叶子节点,如果是叶子节点,则根据节点存储的 key 是否完全相等,判断查询是否成功(乐观策略在这个地方进行)。
- 如果当前节点不是叶子节点,则判断当前节点的前缀和需要查找的是否一致,如果不一致则中止匹配(悲观策略在这个地方进行)。
- 如果前面几轮判断都没查找到,此时则通过
findChild找到下一个节点,继续递归下去查询。
 img
img
内部节点查找算法
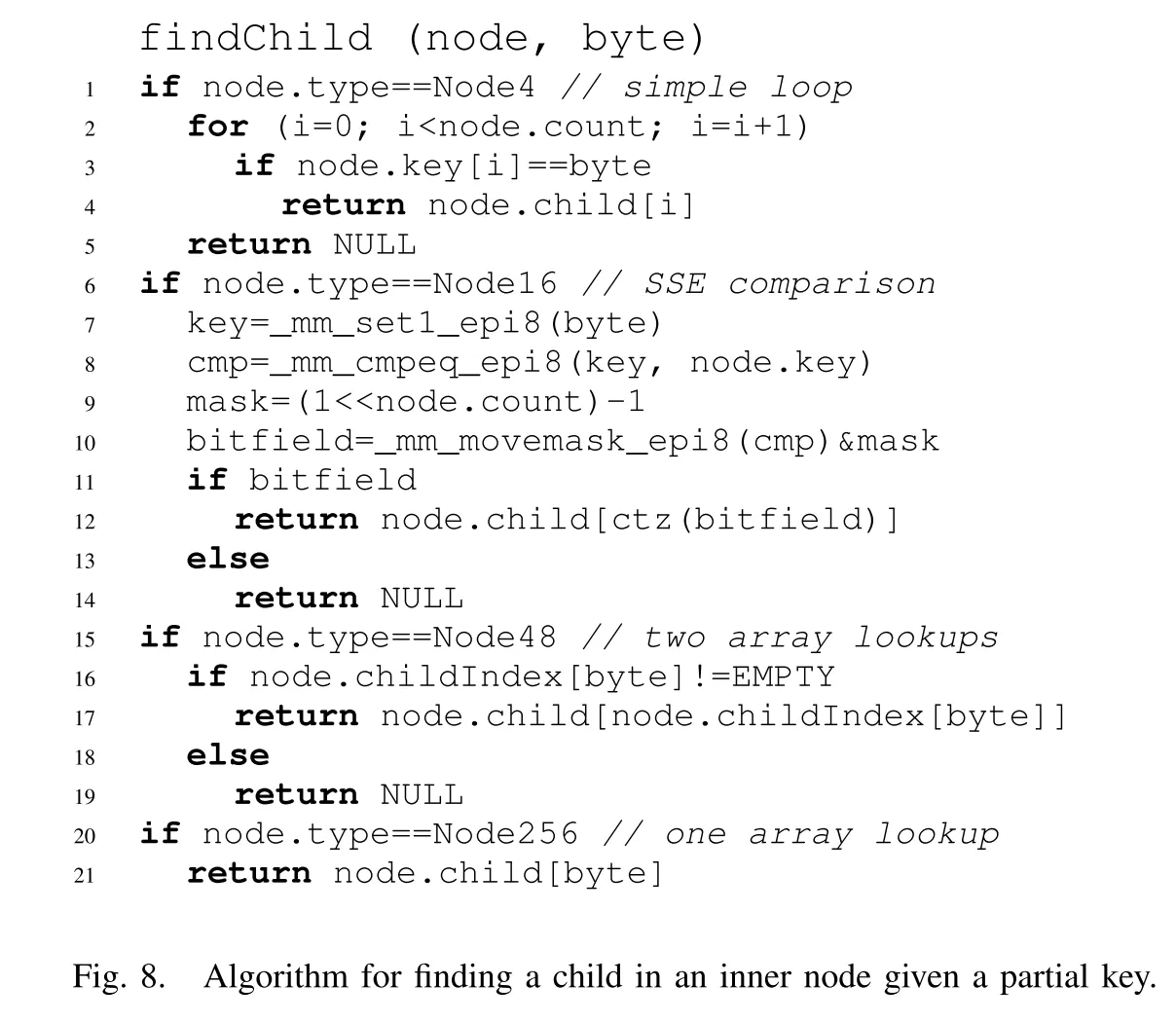
findChild 中主要描述了四种不同的内部节点类型中如何通过 key 找到子节点指针:
- Node4:遍历 key 数组,返回对应的 child。
- Node16:通过 SIMD(不可用时使用二分搜索)来进行数组匹配,找到对应的 child。
- Node48:通过字符序,判断 index 中对应下标存储的 child 数组下标是否为 0,如果不为 0 则根据下标找到对应的 child。
- Node256:直接根据字符序,返回对应下标存储的 child。
Insert
 img
img
插入算法
插入的流程如下:
- 判断节点是否为空,如果为空则用叶子节点替换掉该节点。
- 判断节点是否为叶子节点,如果是则判断 key 是否相同,如果相同则直接返回。如果不同,此时则考虑对 lazy expansion 的拓展操作,将两个节点的公共前缀作为新内部节点的 Key,并将两个节点作为其子节点。
- 如果不是叶子节点,则首先比较前缀,如果前缀不相同,此时将生成一个新节点,将两个节点的公共前缀作为该节点的前缀,并将叶子节点节点和原来的老节点(截断公共前缀后)一起插入到这个新节点中。
- 如果仍然存在下一个节点,则继续向下递归执行,否则先判断节点是否已满,决定是否要调用
grow进行节点扩容,再将叶子节点插入。
Delete
删除算法的思路与插入的大致相同,为其逆向操作,在这里就不过多赘述。如果删除叶子节点后内部节点过少,则会收缩内部节点的容量,如果只有一个子节点,此时则使用 Path Compression 压缩路径。
Bulk loading
在存在大量数据时,使用下面的递归算法可以加速索引的构建:
- 将每个 key 的第一个字节用于基数分区(分为 256 个),并创建相应类型的内部节点。
- 在返回该内部节点之前,通过对每个分区使用下一个字节的 key,来递归加载其子节点。
- 重复步骤 2,直到所有的 key/value 都被插入树中。
并发
传统的细粒度锁的拓展性较差(对于现代 CPU),而无锁结构虽然拓展性好,但是其实现又十分复杂、困难,因此在 ART 中采取了另外两种方法,Optimistic Lock Coupling(乐观锁耦合)和 Read-Optimized Write EXclusion(ROWEX,读优化写排除)。
乐观锁耦合Optimistic Lock Coupling
首先介绍一下什么是锁耦合(Lock Coupling),其是多线程操作树结构时使用的一种同步技术。其有两个锁,当遍历树时,一个锁住父节点,一个锁住当前的节点,然后向下行走,重复这个过程,直到完成对节点的操作。(由于很像螃蟹行走的方式,所以有的人称其为蟹形协议)。
乐观锁耦合就是将乐观锁的思路与锁耦合合并起来,引入了版本号,下面给出悲观锁耦合和乐观锁耦合的对比代码:
 image-20230409030735775
image-20230409030735775
这里引入了两个原语
- readLockOrRestart:不获取锁,等待写锁释放后获取节点当前的版本。
- readUnlockOrRestart:等待写锁释放,检测版本号,如果版本变更则重启读操作。
总结一下,其具有以下范式:
- 读不会获取锁,但是其会检测版本号,如果版本号变更则从根开始重新读。
- 写不会被读阻塞。
- 写需要获取锁,且写入后更新版本信息。
上面的算法需要满足以下条件才能正常运行:
- 调用
readLockOrRestart时,读线程可能会看到不一致的中间状态,为了避免无限循环和访问空指针,必须进行版本检查和指针检查。- 删除节点时不能立即进行回收,需要延迟释放——即将节点标记后,等待没有线程引用时再进行回收。
- 极端情况下,读可能会被多次重启,为了确保读能够执行,可以限制重启的次数,次数达到限制后采用读写锁。
读优化写排除(ROWEX)(乐观读悲观写)
从上面可以看出,当读在进行时,如果有人写入,则会因版本号变更而重启读行为。而如果这种冲突极端严重,则会导致读行为不断重启,甚至可能永远无法执行。因此 ART 通过 ROWEX 来改进这一问题,ROWEX 的核心就是读取不会被阻塞或者重启。
ROWEX 具有以下范式:
- 读不需要加锁、阻塞,也不需要检查版本信息,因此其总是成功的。
- 每个节点中需要维护一个互斥锁,当进行读操作时获取该锁,该锁仅用于阻塞其他写行为。
- 写操作保证同一个节点读一致性,即写操作必须通过原子指令执行。
适配 ROWEX
为了适配 ROWEX,ART 的结构需要进行以下变动:
- 为了支持并发局部修改,内部节点的 key 和指针需要用
std::atomic来管理。 - 对于线性内部结构(Node4、Node16),为了避免排序,采用仅追加的方式,删除则直接将子指针指向空。(虽然不排序时需要遍历整个数组,但是还可以用 SIMD 进行优化),
下面以节点替换和路径压缩为例,说明 ART 中 ROWEX 是如何工作的。
节点替换
当一个节点容量过大/小时,需要替换成其他内部节点类型,此时执行以下流程:
- 对该节点和其父节点进行加锁,并创建一个新节点,将旧节点中的数据全部拷贝到新节点中。
- 通过原子操作修改父节点的子指针,让其指向新节点。
- 解锁旧节点,将其标记为删除。
任何被阻塞的写操作在检测到该节点被标记后,都会重新开始整个插入/删除行为。因此对于读操作来说,读取是始终安全的。
路径压缩
 img
img
对于路径压缩来说,情况又更加复杂,这主要是因为创建节点和更新前缀这两个步骤无法在单个原子操作中完成,如果不做处理,则读取时可以会读到中间状态。
例如上图,一开始树中只有 ARE,ART,通过 Path Compression 将 AR 作为公共前缀。此时插入一个新节点 AS,此时会进行以下操作:
- 创建一个新的内部节点 A,让根节点将子指针从 AR 指向它,它指向 R 和 S。(创建节点)
- 将 R 节点原先的前缀清空(更新前缀)
由于这两个都是独立的原子操作,当我们在完成第一步后,此时的 R 节点仍然保留着前缀,对于它来说此时存储的路径变为了 ARR,这就导致了当前状态的不一致。
为了解决这个问题,每个节点中都需要增加一个 level 字段(代表存储节点的实际高度,即未被 Compression 前应该处于哪一层),这个字段初始化后就不再变更,其保证了中间状态始终安全。
- 如果一个读取操作在某个节点看到了中间状态,它可以通过检查该节点的 level,判断出该节点的前缀是否已经被截断。如果前缀已经被截断,则读取操作可以跳过该节点,继续向下搜索。如果前缀没有被截断,则读取操作可以根据该节点的 level 字段,查找出缺失的 key。
- 以上图为例,当我们看到蓝色节点的中间状态时,会直接跳过该处的前缀(此时 level 应当为 3,检测到 2 说明为中间状态)。